


Opening a Can of Worms, Stirring Up a Hornet’s Nest, Stepping into a Minefield, Sailing into Uncharted Waters, Opening Pandora’s Box… whatever idiom you prefer, they all pretty accurately describe the process of data migration.
Data migration is simple right? Move the data from point A to point B, and voilà, you’re migrated right?
Wrong.
The simple fact is that data migration is often one of the most underestimated parts of a project, and can lead to large delays and budget overruns.
Fail to plan — plan to fail.
We’ve all heard that expression before: It’s cliché and it’s catchy. And it’s also true. The first step to a successful migration is to create a migration strategy – a series of steps that you’ll go through, and a timeline associated with each step, that will get your data moved onto your new platform with the least amount of disruption to your end-users, and preserve the greatest degree of data integrity possible.
We’ve compiled a list of considerations for your data migration strategy.
Don’t underestimate the time it takes to migrate
The first step in crafting your migration strategy is to ensure you allot enough time for it in your overall project plan. Data migration could easily take one or two months or more depending on many factors. How much data you have, the performance of your sandbox environments, the efficiency of your database indexes, the number of tables, the number of complex joins, working with a VPN, the type of database you’re using, licensing restrictions, and others all factor into the time it takes to work with your data. So be sure to leave a lot of time for this phase. It’s better to allot more time and finish early than less time and be late.
To give some context, when we did our first CLASS to Avocado migration, it took close to 1,000 hours of developer and business analyst time to map, model and migrate all of the data to a successful degree of integrity.
Understand the lay of the land

The first phase of your migration plan needs to be an analysis of the existing environment(s). This is easily one of the most, if not the most, challenging piece to the puzzle. You’re going to need to understand many, many factors about the existing environment(s) to get a true sense of what your strategy will be.
For instance you need to understand what your export options are:
- Can you create a cloned sandbox environment for your existing database/software?
- Can you query the existing database directly?
- Do you need to use a proprietary or obscure query language?
- Can you export to a spreadsheet?
- Can you get a full database dump?
- Do you need any additional licenses to work with a backup or sandbox?
- What is the character encoding of my data export?
These answers all impact the timing and approach of your migration strategy.
You also need to get a deep understanding of how the data interacts with the software, website or app. For instance a “customer” record might pull data from a dozen different database tables. Some tables may have 1-to-1 relationships, some may have 1-to-many or many-to-1. Some tables may need to be joined in a specific order to retrieve a full, valid record. Understanding your data structure is key here.
And that bring us to the next point.
Model your existing data
This goes hand-in-hand with getting the lay of the land. As your knowledge of what you’re working with begins to grow, it’s of paramount importance that you model the existing data. Some database management systems have some enterprise tools that allow you to automagically* generate database diagrams / models that show you exactly how each table relates to each other.
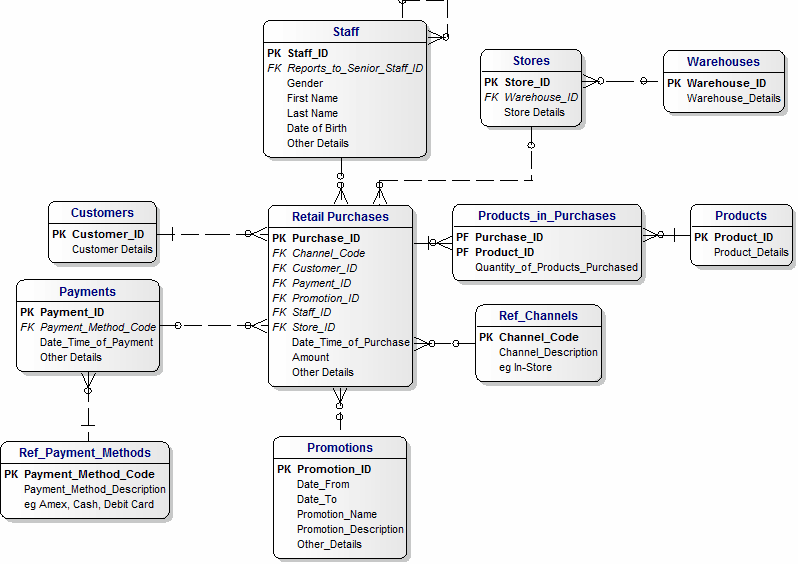
There are a ton of free tools available to help create data models like the one shown above. Archi, QuickDBD, DBDesigner and SqlDBM are a few options available to try out. How you decide to model your data is completely up to you, the key is that you do it.
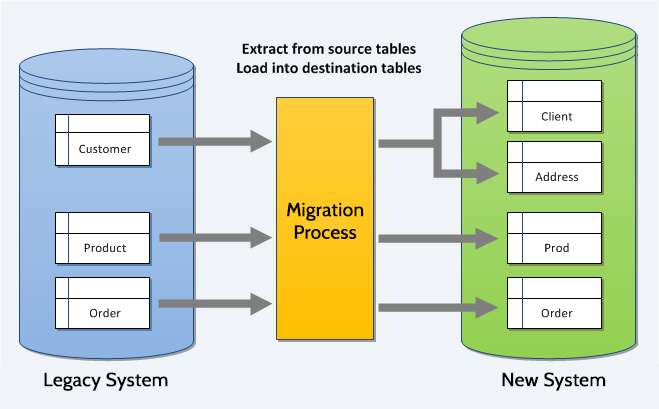
Map your existing data model to your new data model
This is where the rubber meets the road on your migration planning. Once you have your existing data modeled you need to map it to your new system’s data model. This will almost certainly involve some level of data manipulation. Tables or fields may need to be split or concatenated depending on the new structure. Some data may need to be abandoned because it’s not used in the new system. Placeholder data may need to be inserted because it doesn’t exist in the old system, but is required in the new system. This process will help identify data manipulation needs, identify gaps in the data models, identify orphaned data, and help identify the needs of your automated migration scripts.
Have a realistic target for your acceptable percentage of “garbage data” before you begin
One of the things that often gets overlooked during a migration project is having an acceptable margin of error for legacy data. We want to preserve it all, no matter how poorly it was entered into the legacy system. Often times we’re migrating away from a system which allowed a lot of free form text, didn’t preserve the integrity of data and didn’t validate proper formatting for specific data types. As an organization you’ll need to determine what your acceptable margin is, and for what types of data. You should do this before you start, so that when you do end up with bad data (because you will) you don’t get too hung up on it.
Balance your time between automated and manual migration
This goes hand in hand with the previous point. In addition to your acceptable margin of error, you also need to ensure you balance your time between continually iterating on your automated migration scripts and just moving the outliers over manually.

At a certain point there is diminishing rate of return for an automated migration. Having a programmer spend dozens (or hundreds) of hours creating logic and exceptions to parse out poorly formed data eventually becomes more expensive and time consuming than just manually creating records in the new system. A little copy-paste is just what the doctor ordered sometimes. And, for the edge cases where data really is just garbage, you can lean on your acceptable margin of error and keep moving.
Audit, audit and then audit some more
The moment of truth for any migration project is the auditing / testing phase. You’ve spent countless hours analyzing and mapping your data. Scripts have been written and rewritten and rewritten again. You’ve finally got all the data in within your acceptable margin of error… but you don’t yet have proof that the process has been a success. Maybe something got missed. Maybe there was a gotcha that was hiding in plain sight.
Of course your migration team will have been testing throughout the iterative scripting process, so it’s unlikely you’ll get to the end only to find out you have a major disaster on your hands. However, it is definitely of paramount importance that you go through a rigorous testing / auditing process to ensure the integrity of your data. Once you cut over to your new system fixing issues becomes exponentially more difficult.
The best audit strategies involve a combination of automated verification and manual spot-checks. You’ll want to essentially run side-by-side tests and evaluate the output to ensure that customer, account, order, product and all other types of migrated records are showing the same data in the new system as in the old system. Once you’ve run enough tests and feel confident that the migration was a success, you’re ready to cut-over to the new system.
Final Thought
A final tip for your migration projects, whether you’re migrating onto Avocado or not, is that ideally you can keep the legacy system up and running for a while afterwards. This will allow you to verify any legacy data if you do find records which don’t seem to add up properly. You will need to determine if this is doable, and for how long, based on a number of factors, with licensing and cost being the two primary ones.
Just remember to go into it with your eyes wide open. Expect some pain, but remember to breathe deeply and be prepared with a plan.
*Yes, this was an intentional use of a non-existent, but funny to say word.
Michael is a digital veteran, with over 20 years experience in the internet and software development and delivery space. Michael began his career as a graphic designer, moving into web development and programming, then onto leading development teams and eventually moving into the client service, strategy and sales side of business.